
 The Character Set feature is under the 'Other' drop-down menu.
This feature displays all Unicode characters, and allows the user
to copy them into a document.
The Character Set feature is under the 'Other' drop-down menu.
This feature displays all Unicode characters, and allows the user
to copy them into a document.
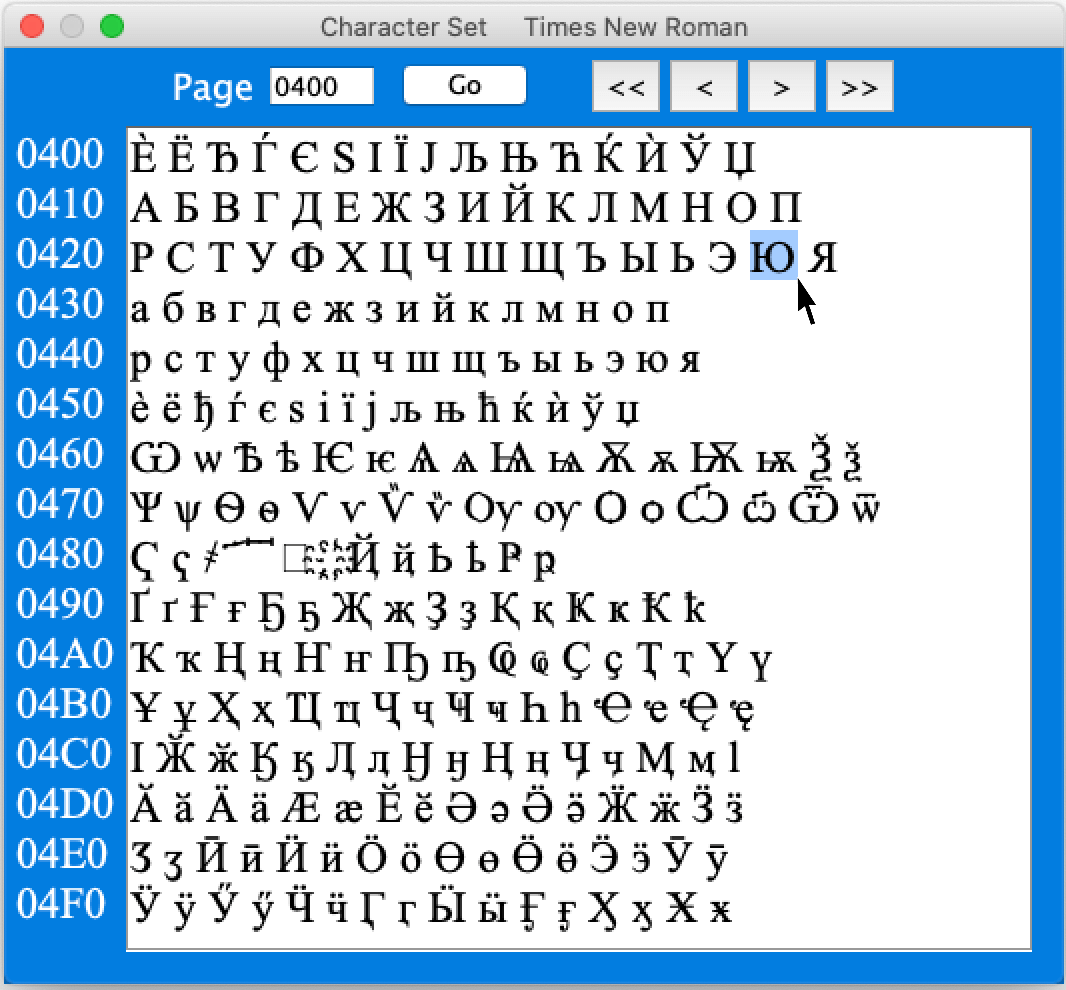
The code-space (65536 codes) is divided into 256 pages of 256 codes. Click on the arrow buttons < and > to go to the previous or next page. The double arrows, << and >> are for jumping 16 pages. If you know the code (in hexadecimal) of the character you wish to see, type it into the Page field at the top of the dialogue and click on Go.
You can copy characters, even entire alphabets, from the dialogue into the text which you are editing. Simply highlight the character or characters to copy, (by dragging the cursor with the left mouse button held down), and use Ctrl‑c to copy them to the clip-board. Next, click on the target location in your text, and use Ctrl‑v to paste in the characters.
Generally, the hexadecimal code in the left column represents the left-most character in the character window. In screen shot shown above, the code for Russian A is 0410, and the code for П is 041F. However, because Arabic and Hebrew texts run from right to left, the order of these characters is reversed. In the screen shot below, the code 05D0 represents the Hebrew letter aleph, which is show highlighted on the right-hand side.
