
There are many ways to encode characters. Internally, Simredo uses Unicode. The Conversion Table function allows the user to convert various character encodings and transliterations to and from Unicode.
For example, lexicographers use a transliteration called Buckwalter to represent Arabic script with Roman letters. The Arabic sentence ".اسمي كليف" in Buckwalter is "Asmy klyf." Simredo has a conversion table named Arabic-BW, which is used to convert to and from Buckwalter.
In addition, the Conversion Table feature allows the user to define his/her own conversion tables, as described below.
Select 'Conversion' from the 'Other' menu. A dialogue window similar to the one below will appear.
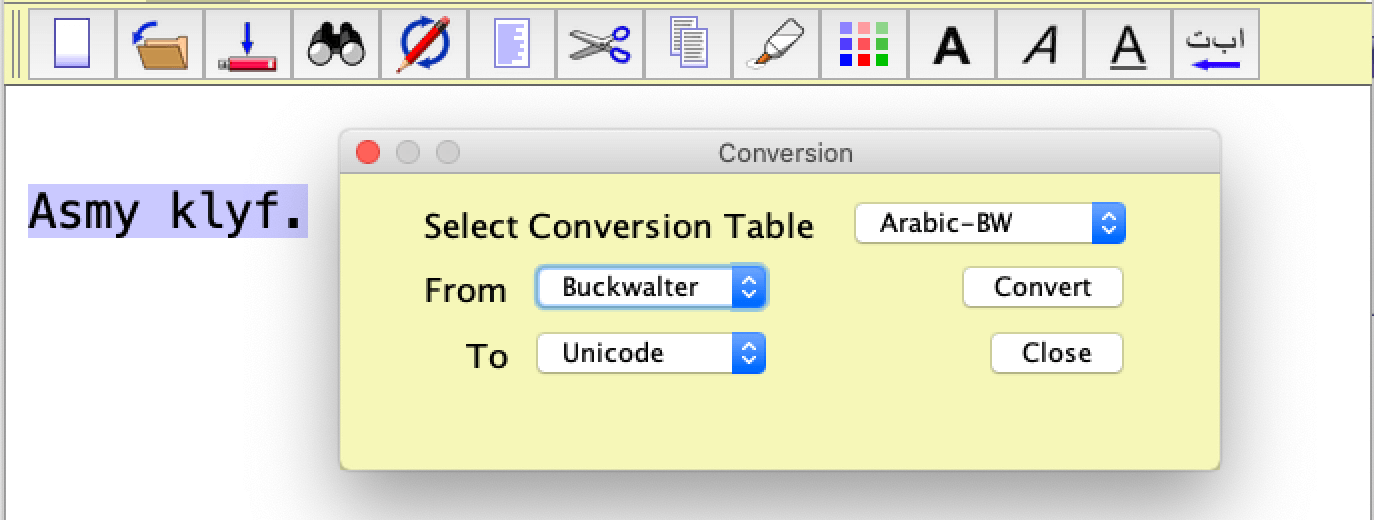
There are three drop-down menus. The one at the top right is used to select the conversion table. In the screen shot shown above, the Arabic-BW table is selected. The second are third menus are used to select the encodings to convert from (Buckwalter) and to (Unicode).
Suppose a text file contains the text "Asmy klyf."
Clicking on the Convert button will convert it to Unicode, as shown below:
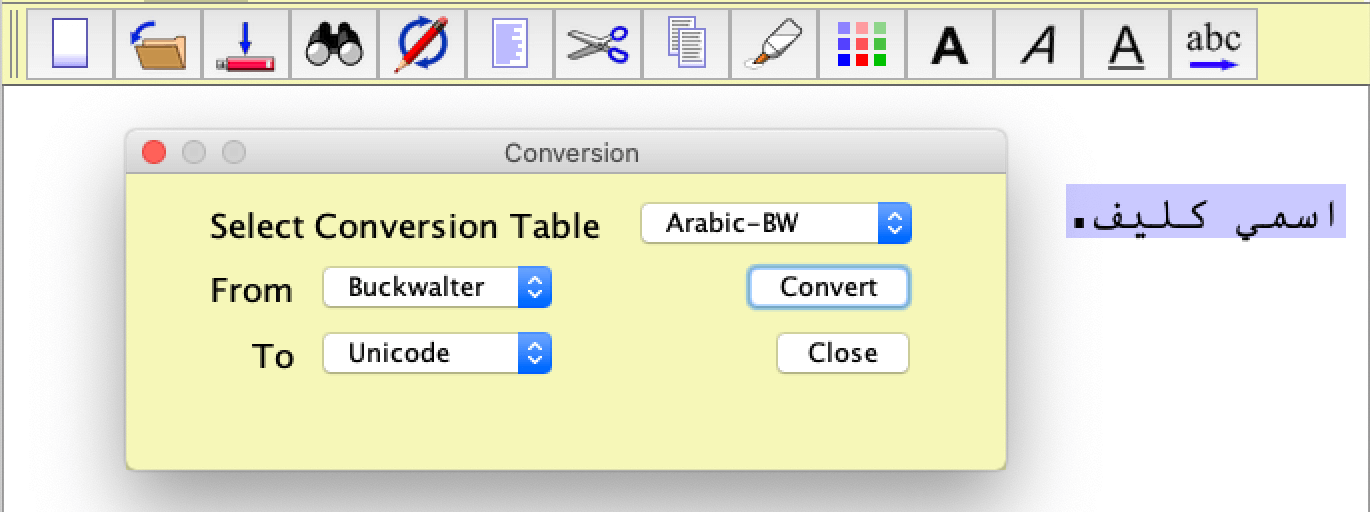
Important: This feature only converts text which has been selected. In the screen shots above, selected text is shown with a purple background.
The Vietnamese conversions are defined in a file called Vietnamese.kon. This file contains a line corresponding to VIRQ and another corresponding to Unicode, as shown below. (The actual lines in the file are very long, so only the first few characters are shown here.)
VIRQ,A^',a^',A^`,a^`,A^?,a^?,A^~,a^~,A^.,a^.,A(',a(',A(`,a(`,
Unicode,Ấ,ấ,Ầ,ầ,Ẩ,ẩ,Ẫ,ẫ,Ậ,ậ,Ắ,ắ,Ằ,ằ,
When the conversion function is executed, each letter sequence in the VIRQ list is converted to the corresponding character in the Unicode list (except for the first item, which is the name of the list).
Conversion table files must be in UTF‑16 Big Endian format. As with keymap files, empty lines and lines beginning with a space are ignored. (Putting a space in front of a line is useful for entering comments.) Character strings are separated by commas. If you need to convert the comma itself, use the backslash‑u code \u002c to represent it. (In fact, you can use the backslash‑u code to represent any Unicode code.)
Conversion table files must have an extension of kon, for example, Armenian.kon, Vietnamese.kon, etc., and must be located in a folder called 'simredo', which the installation program creates..
The Show Character Set feature can be useful when creating new conversion tables. Characters can be copied from this dialogue and pasted into the new conversion table.
Programmers and HTML-designers may find the conversion table EscCodes particularly useful. This conversion table enables you to convert between the following encodings:
Unicode values above 127, eg., Ĝ
Backslash-u, eg., \u011c
Decimal HTML, eg., Ĝ
Hexadecimal HTML, eg., Ĝ
The above conversions could not be implemented with simple comma separated lists, so they are hard-coded into Simredo. The file EscCodes.kon contains only the names of each kind of escape code.
The conversion routines for Esperanto's accented letters are intelligent. As with escape code conversions, they could not be implemented with simple lists, so they are also hard-coded.
When you convert from the h-method, Simredo uses the spelling dictionary to test whether letter pairs with h should or should not be converted. In this way, a sentence such as 'Shi iris al la flughaveno' is correctly converted to: 'Ŝi iris al la flughaveno.'
The lists in Esperanto.kon are provided for reference. They are not actually read by Simredo. If you want to create a new set of conversions for Esperanto, I suggest that you copy Esperanto.kon to Esperanto2.kon, and make changes in the new file.