
The smallest unit of information is called a bit. In computers, a bit can be 0 or 1. Computers usually deal with groups of 8 bits, called bytes. A byte can store a number from 0 to 255 inclusive; in other words, a byte of information can represent 256 codes. In order to represent a larger number, more bytes are needed.
In a text file, the number (or code) in a byte represents a letter or symbol. For example, the number 97 represents the letter a, 98 represents b, etc. One of the early standards, which became the basis for more modern standards, is ASCII (American Standard Code for Information Interchange). ASCII defines characters and functions for the numbers 0 through to 127. It includes the English alphabet, the numbers 0 to 9, some special characters (# $ % etc.) and some codes to control printers and teletype machines. It doesn't define codes above 127, and doesn't include the accented letters which are necessary for European Languages.
Because ASCII is very limited, the International Organization for Standardization, ISO, created standards for codes above 127. One of these standards, probably the most used, is ISO 8859‑1, which is usually called Latin 1. Latin 1 includes the accented letters which are necessary for most western European languages, i.e. French, German, Spanish, Norwegian etc. But there are many other languages, besides western European ones, and Latin 1 doesn't have enough codes to include them. For other European languages, there are other standards. The entire set ranges from ISO 8859‑1 to ISO 8859‑10. These are single byte standards; i.e. each defines 256 codes. The lower codes, 0 to 127, are identical with ASCII, and the upper codes define the accents for various languages. The accented letters for Esperanto are in Latin 3 (ISO 8859‑3). Esperantists used to use this standard in their documents and homepages, before Unicode became popular.
Some languages have very large numbers of characters, for example Chinese, Japanese and Korean. Because single byte standards cannot represent such languages, double byte standards were created. With two bytes, 65536 characters can be represented (256*256 = 65536).
For Asian languages, there is often more than one popular standard. For example, Japanese use mainly S‑JIS (Shift Japanese Industrial Standard) in Windows systems, and EUC (Extended Unix Code) in Unix systems. Standards for Asian languages can theoretically represent 65536 characters, but in practice they define less than 10000. The Japanese standards include Japanese syllabaries, Chinese characters, and letters for some other languages, but not all. Using S‑JIS, Japanese and English can be represented in the same document, but Japanese and Arabic cannot.
To solve the problem of multiple and overlapping standards, Unicode was developed. Unicode is a new double byte international standard, which defines codes for all major languages.
Unicode isn't perfect. For example, it doesn't define codes for every Chinese character which has ever been written, but it's good enough for ordinary Chinese texts. Lately, more and more systems and programs are starting to support Unicode, and hopefully it will reduce the chaos of character standards.
Some points to remember:
- ASCII is a single byte standard which defines codes from 0 to 127.
- Latin 1 (ISO 8859‑1) is a single byte standard which defines codes from 0 to 255.
The first 127 codes are identical to ASCII. - Unicode is a double byte standard which defines tens of thousands of codes and includes
all major languages. The first 256 codes are identical with Latin 1.
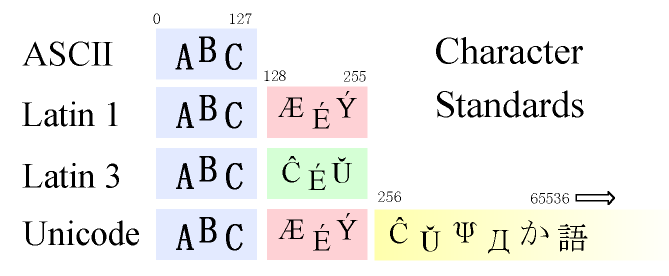
There are several different ways of representing Unicode. It's important to understand the differences.
The ordinary form of Unicode is called UTF‑16 (Unicode Transformation Format -16). The 16 means that each code has 16 bits (two bytes, 2*8 = 16 bits).
Different computers store numbers differently. Consider the number 1077 (base 16). Two bytes are necessary to store this number: one stores the most significant part (10), and the other stores the least significant part (77). But the order of the bytes in memory depends on the processor of the computer. In other words, some computers write 10, 77, and others write 77, 10. The first method is called Big Endian and the second is called Little Endian.
Because of this, there are two forms of UTF‑16: Big Endian and Little Endian. Microsoft's Word writes out Unicode using Little Endian. Big Endian is recommended for the Internet. UTF‑16 files usually start with a code which identifies them as Big Endian or Little Endian.
UTF‑16 files are twice as big as single byte files; e.g. Latin 3 files. Those who have many text documents don't want to double the space which they take up. Because of this, the Unicode Consortium created a compact form of Unicode: UTF‑8.
In text files of European languages which use a Latin alphabet, most of the letters do not have accents. For example, in an ordinary Esperanto text, only 2 or 3 percent of the letters have accents. A lot of space can be saved, if frequently used letters are encoded with only one byte.
UTF‑8 represents the same codes as UTF‑16, but codes them in such a way, that the most often codes, those below 128, need only one byte. Codes between 128 and 1023 need two bytes, and codes above 1023 need three bytes.
The Unicode codes below 128 are the same as ASCII. Because of this, if a UTF‑8 file happens to have only Latin letters, without accents, it is identical with ASCII. Therefore UTF‑8 is more compact than UTF‑16, if the text is mostly made up of Latin letters. But UTF‑8 is not recommended if the text is Japanese or Chinese, because it needs three bytes to represent these characters. In this case, UTF‑16 is preferable.
Please understand that UTF‑8 is not a subset of UTF‑16. It represents the same codes which UTF‑16 represents. It's possible to convert from UTF‑16 to UTF‑8 and back, without loosing data.
The 8 in UTF‑8 means that the codes in UTF‑8 are usually 8‑bit (one byte).
I hope that you found this article useful. If you have corrections or suggestions, please contact me.
|
Regards,

|