
La plej malgranda unuo de informo nomiĝas bito. En komputilo, bito povas esti 0 aŭ 1. Komputiloj kutime traktas grupojn da 8 bitoj, kiuj nomiĝas bitokoj, aŭ laŭ la Angla, bajtoj. Bitoko povas enteni numeron inter 0 kaj 255 inkluzive; alivorte, bitoko da informo povas reprezenti 256 kodojn. Por reprezenti pli grandan numeron, oni bezonas pli da bitokoj.
En dokumento, la numero (aŭ kodo) en bitoko reprezentas literon aŭ signon. Ekzemple, numero 97 reprezentas la literon a, 98 reprezentas b, ktp. Unu de la fruaj normoj, kiu fariĝis bazo de pli modernaj normoj, estas Askio (nacilingve ASCII - American Standard Code for Information Interchange). Askio difinas signojn kaj funkciojn por numeroj de 0 ĝis 127. Ĝi enhavis la anglan alfabeton, la ciferojn 0 ĝis 9, kelkajn specialajn signojn (# $ % ktp.) kaj kelkajn kodojn por regado de presiloj kaj teletajpiloj. Ĝi ne difinas literojn por kodoj super 127, kaj ne inkluzivas la supersignitajn literojn kiuj necesas al eŭropaj lingvoj.
Ĉar Askio estas tre limigita, la Internacia Norma Instanco, ISO, kreis normojn por la kodoj super 127. Unu de tiuj normoj, eble la plej uzata, estas ISO 8859‑1, kiu kutime nomiĝas Latino‑1. Latino‑1 enhavas supersignitajn literojn kiuj necesas por okcidentaj eŭropaj lingvoj, kiel ekzemple la franca, la germana, la hispana, la norvega, ktp. Sed estas aliaj eŭropaj lingvoj, krom la okcident-eŭropaj. Latino‑1 ne havas sufiĉe da kodoj por inkluzivi ilin. Por ili estas aliaj normoj. La tuta gamo estas ISO 8859‑1 ĝis 10. Ĉi tiuj estas unu-bitokaj normoj; tio estas, ĉiu difinas 256 kodojn. La malsupraj kodoj, 0 ĝis 127, estas identaj kun Askio, kaj la supraj kodoj difinas supersignitajn literojn por diversaj lingvoj. La supersignitaj literoj de Esperanto troviĝas en Latino‑3 (ISO 8859‑3). Esperantistoj iam uzis ĉi tiun normon por siaj dokumentoj kaj interretaj paĝoj, antaŭ ol Unikodo fariĝis populara.
Iuj lingvoj havas tre grandajn nombrojn da signoj, ekzemple la ĉina, la japana, kaj la korea lingvoj. Ĉar la unu-bitokaj normoj ne kapablas reprezenti tiajn lingvojn, oni kreis du-bitokajn normojn. Per du bitokoj, oni povas reprezenti 65536 signojn (256*256 = 65536).
Por aziaj lingvoj, ofte ekzistas pli ol unu populara normo. Ekzemple, Japanoj uzas ĉefe S‑JIS (Shift Japanese Industrial Standard) en Vindozaj sistemoj, kaj EUC (Extended Unix Code) en Uniksaj sistemoj. Normo por azia lingvo povas teorie reprezenti 65536 signojn, sed en praktiko ili difinas malpli ol 10000. La japanaj normoj inkluzivas japanajn silabarojn, ĉinajn ideogramojn, kaj literojn por iuj aliaj lingvoj, sed ne ĉiuj. Per S‑JIS oni povas reprezenti la japanan kaj la anglan en la sama dokumento, sed ne la japanan kaj la araban.
Por solvi la problemojn de multaj kaj koliziantaj signaj normoj, oni evoluigis Unikodon. Unikodo estas nova, du-bitoka internacia normo, kiu difinas kodojn por ĉiuj ĉefaj lingvoj.
Unikodo ne estas perfekta. Ekzemple, ĝi ne difinas kodojn por ĉiuj ĉinaj ideogramoj kiuj iam ajn uziĝis, sed ĝi sufiĉas por ordinaraj ĉinaj tekstoj. Nuntempe, pli kaj pli da sistemoj kaj programoj traktas Unikodon, kaj espereble ĝi malpliigos la ĥaoson de signaj normoj.
Kelkaj punktoj por memori:
- Askio estas unubitoka normo, kiu difinas kodojn de 0 ĝis 127.
- Latino‑1 (ISO 8859‑1) estas unubitoka normo, kiu difinas kodojn de 0 ĝis 255.
La unuaj kodoj estas identaj kun Askio. - Unikodo estas dubitoka normo, kiu difinas dekmilojn da kodoj kaj inkluzivas
ĉiujn ĉefajn lingvojn. La unuaj 256 kodoj estas identaj kun Latino‑1.
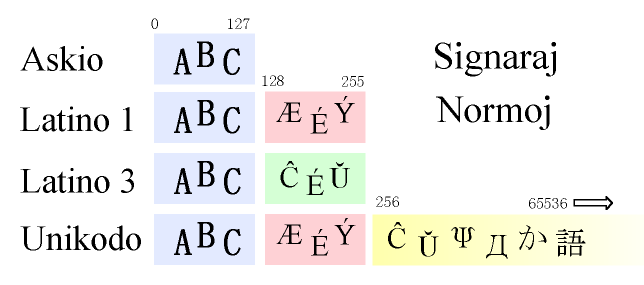
Estas pluraj malsamaj manieroj por reprezenti Unikodon. Estas grave kompreni la diferencojn.
La ordinara formo de Unikodo nomiĝas UTF‑16 (Unicode Transformation Format -16). La 16 signifas ke ĉiu kodo havas 16 bitojn (du bitokoj, 2*8 = 16 bitoj).
Diversaj komputiloj tenas numerojn en memoro malsame. Konsideru la numeron 1077 (deksesuma). Oni devas uzi du bitokojn por teni tiun numeron: unu tenas la pli signifan parton (10), kaj la alia tenas la malpli signifan parton (77). Sed la ordo de la bitokoj en memoro dependas de la procesoro de la komputilo. Alivorte, iuj komputiloj kutime skribas 10, 77, kaj aliaj kutime skribas 77, 10. La unua metodo nomiĝas pezkomenca, kaj la dua, pezfina.
Pro ĉi tio, estas du formoj de UTF‑16: pezkomenca kaj pezfina. Word de Mikrosofto uzas pezfinan UTF‑16on. Oni rekomendas pezkomencan UTF‑16on en la Interreto. UTF‑16a dokumento kutime komenciĝas per kodo kiu indentigas ĝin kiel pezkomencan aŭ pezfinan.
UTF‑16a dokumento estas duoble pli granda ol unubitoka dokumento; ekzemple Latin3a dokumento. Tiuj kiuj havas multajn tekstajn dokumentojn, ne volas duobligi la spacon kiun ili okupas. Tial, la Unikoda Unio kreis kompaktan formon de Unikodo: UTF‑8.
En tekstoj de Eŭropaj lingvoj kiuj uzas latinan alfabeton, la plejo da literoj ne havas supersignojn. Ekzemple, en ordinara Esperanta teksto, supersignitaj literoj estas nur 2 aŭ 3 procentoj de la literoj. Oni povas ŝpari multe da spaco, se oni kodas oftajn literojn per nur unu bitoko.
UTF‑8 reprezentas la samajn kodojn kiujn UTF‑16 reprezentas, sed kodas ilin tiel, ke la plej oftaj kodoj, tiuj sub 128, bezonas nur unu bitokon. Kodoj inter 128 kaj 1023 bezonas du bitokojn, kaj kodoj super 1023 bezonas tri bitokojn.
La Unikodaj kodoj sub 128 estas samaj al Askio. Pro tio, se UTF‑8a dokumento hazarde havas nur latinajn literojn, sen supersignoj, ĝi estas identa kun Askio. Do, UTF‑8 estas pli kompakta ol UTF‑16, se la teksto estas plejparte latinlitera. Sed UTF‑8 estas malrekomendinda se la teksto estas japana aŭ ĉina, ĉar ĝi bezonas tri bitokojn por reprezenti tiujn signojn. Tiukaze, UTF‑16 estas uzinda.
Bonvolu kompreni ke UTF‑8 ne estas subaro de UTF‑16. Ĝi reprezentas la samajn kodojn kiujn UTF‑16 reprezentas. Oni povas konverti dokumenton de UTF‑16 al UTF‑8, kaj reen, sen perdo de informo.
La 8 en UTF‑8 signifas, ke la kodoj en UTF‑8 estas kutime okbitaj (unu bitoko).
Mi esperas ke vi trovis ĉi tiun artikoleton utila. Se vi havas korektojn aŭ sugestojn, bonvolu sendi ilin al mi.
|
Dankon,

|